Hinreddit
Reddit in Heterogeneous Information Network

1. Hateful Post Classification
As countless social platforms are developed and become accessible nowadays, more and more people get used to posting opinions on various topics online. The existence of negative online behaviors such as hateful comments is also unavoidable. These platforms thus become prolific sources for hate detection, which motivates large numbers of scholars to apply various techniques in order to detect hateful users or hateful speeches.
In our project, we plan to investigate contents from Reddit, which is a popular social network that focuses on aggregating American social news, rating web content and website discussion, that carries rich potential information of contents and their authors. Our goal is to classify hateful posts from the normal ones. Being able to identify hateful posts not only enables platforms to improve user experiences, but also helps to maintain a positive online environment. We would like to stress that the boundary of 'hate' is vague and there is no correct nor consolidated definition of 'hatefulness,' our classification of hateful posts depends only on a unified definition within our team, which we divide into the categories of severe_toxic, toxic ,threat, insult, and identity_hate. We all agree that other people's recognition of "hate" may be but not limited to these four categories, and our labeling method allows full freedom of other definition of "hatefulness."
If our project was successful, we would have built an application, hinReddit, which helps identify hateful posts for Reddit based on users' posting and replying network. Similarly, others can apply our process on different social platforms.
2. Related Works
Studies regarding the detection of hateful speech, content, and users in online social networks have been manifold. In the report Characterizing and Detecting Hateful Users on Twitter, the authors present an approach to characterize and detect hate on Twitter at a user-level granularity. Their methodology consists of obtaining a generic sample of Twitter’s retweet graph, finding potential hateful users who employed words in a lexicon of hate-related words and running a diffusion process to sample more hateful users who are closely related in the neighborhood to those potential ones. However, there are still limitations to their approach. Their characterization has behavioral considerations of users only on Twitter, which lacks generality to be applied to other Online Social Networks platforms. Also, with ethical concerns, instead of labeling hate on a user-level, we believe that detecting hate on a post-level will be more impartial.
3. The Data
Our project includes a couple different datasets:
Main dataset used for our project analysis
This is a dataset we will obtain from Reddit through API. We use the API called PushShift to obtain Reddit post information, including post text, title, and user ids who reply to either the post itself or any of the reply below the post and the comments that it provided. We use PushShift because it offers a specific API to obtain the flattened list of repliers' ids and takes considerably less time than doing the same with PRAW. After a brief EDA on the most popular 124 subreddits, we select 47 subreddits in which 37 are quarantined and 10 are normal. A subreddit is quarantined if Reddit decides its content is too offensive for average reddit users, and thus we expected to obtain more hateful posts from these subreddits.
Our raw data includes three kinds of files: the csv files that contain the basic information of each post, the json files that contain the post ID along with all of the comment ID belongs to it, and the csv files that contain the information of each comment.
Kaggle Toxic Comment Classification Dataset
This dataset includes information of hundreds of thousands of wikipedia comments along with multiple negative labels downloaded from Kaggle. We will be mainly using this dataset to train a nlp classifier model to label our reddit post data before we use it for HIN learning.
4. Labeling
Since the original data obtained from Reddit is not labeled, we will be using a RNN and bidirectional layers, through python library keras, as well as pre-trained word representation vectors from GloVe, to label the Reddit posts before we use it for our project main analysis.
By following a tutorial of using keras and the pretrained word vectors, we will train a multi-label NLP model with kaggle labeled dataset of wikipedia comments detailed in Datasets. We will save this model in directory interim. This multi-label model then can be used to calculate each Reddit post or comment a score between 0 to 1 for each of the label toxic, severe_toxic, threat, insult, identity_hate.

The labeling process for a single post is shown above and explained as follows: We first obtain scores for the post itself if it has textual content. Then, we also obtain scores for all of its comments to compute an average of all five labels. We then compute total scores for the post by adding scores of post content and its comments. We then compute the max of all five total scores, and if the max value is greater than the threshold, we classify the post as 'hateful'. In our project, we set the threshold to 0.5. If the post is removed it will be labeled as deleted and the NA post will also be labeled as NA.
In this way, we can also label those posts which are missing textual content by making use of its comment data. Moreover, with this labeling process, we are defining hateful posts so that they not only include those that demonstrate hatefulness in its content, but also those that stir up negative discussions in comments and replies.
5. Exploratory Data Analysis
Label Statistics
As you may know, Reddit has already banned lots of subreddit that contained explicit or controversial materials. Thus in order to discover more hateful speech, we researched online and find out a list contained both banned and quarantined subreddits. Quarantined subreddits are subs that host no advertisement, and Reddit doesn't generate any revenue off toxic content. People can still access those subs, but there will be a prompt warns telling people about the content on the sub. We have selected around 37 quarantined subreddit along with 10 normal subreddits.
By using the data ingestion pipeline, we have successfully extracted 5,000 posts from each of the 47 subreddits which is 235,000 posts in total. Some basic statistics about the comments are shown in the tables below.
Proportion of Each Label
We then look at the labels at a higher level without grouping them into different subreddits. The table below shows the distribution of the labels among posts.
| label | % post |
|---|---|
| deleted | 10.8% |
| benign | 84% |
| hateful | 4.7% |
Number of Comments
Another feature could be the number of comments under each post. The average length of comment for posts labeled hateful is relatively smaller than that for posts labeled as benign.
| label | min | max | mean |
|---|---|---|---|
| benign | 0 | 9783 | 24 |
| hateful | 0 | 2043 | 16 |
Length of Text Content
Dig deeper into the content of the posts for different labeling groups, we investigate on the length of the content. From the table below, it shows that even though the min and max of the length of content in each group is around the same, the average length of content for posts that are labeled hateful is more than double of the average length of content for posts that are labeled benign. Thus we can add this as one of our feature.
| label | mean | min | max |
|---|---|---|---|
| benign | 82.87 | 1 | 7549 |
| hateful | 176 | 1 | 7048 |
Upvote Score
Moreover we also find difference in score for the two groups, the mean score of benign posts are generally higher than those of hateful posts.
| label | mean_score |
|---|---|
| benign | 32 |
| hateful | 11 |
Vocabulary
Moreover, in order to evaluate the quality of the label, we have also done some textual analysis. We find out the top 30 words in posts after removing stop words for each of the groups. However, we have also removed about 20 words that appeared in both groups. Those should be the common words that appeared in the conversation and thus is not helpful as a feature for our classification.
| malign_word | count | benign_word | count |
|---|---|---|---|
| fuck | 5,835 | amp | 13,155 |
| nigger | 4,078 | work | 12,508 |
| fucking | 3,233 | feel | 12,388 |
| shit | 2,907 | right | 12,208 |
| place | 2,713 | gt | 11,256 |
| sex | 2,200 | things | 11,244 |
| started | 1,840 | new | 11,002 |
| ass | 1,800 | need | 10,629 |
Interaction b/w Posts & Users
We have 483,173 unique users in our data. 7% of users in our data have been involved with hateful posts. Among them, 44.26% of users have themselves create posts/comments labeled as hateful.
| Percentage of users only post once | Proportion of users post only in 1 subreddit |
|---|---|
| 44.95% | 85.24% |
We can observe that nearly half of the users post only once and are not active authors on Reddit. Most of them are only involved within one subreddit, thus their behavioral movements are representative of that subreddit.
In addition to general user, we also investigate hateful post users' behaviors specifically.
| Proportion of users who only post once among all users engaged in hateful post | Proportion of users who post only in 1 subreddit among all users engaged in hateful post |
|---|---|
| 21.01% | 70.03% |
We can observe that users who engage in hateful post are more active authors compare to general users.
Some users engage in both benign and hateful posts, and we found that among users who have engaged in hateful posts, 14% of their written posts and comments are classified as hateful.
6. Graph Extraction
the graph structure is shown as below:
Graph 1
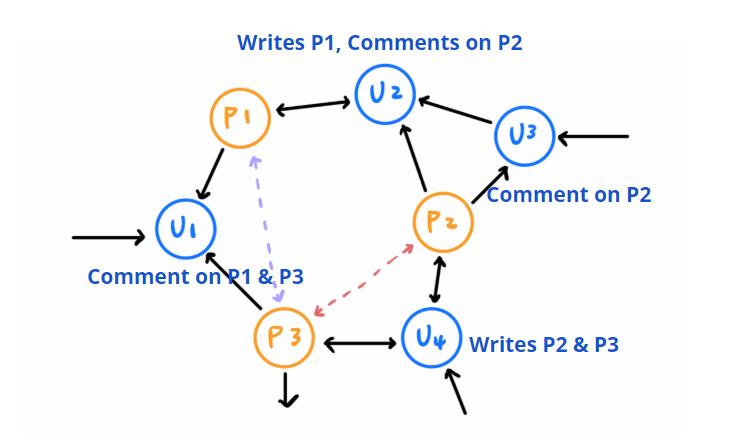
Graph 1 consists two kind of nodes: post nodes and user nodes, and represents three kinds of relationships: authorship, involvement, and reply. The matrices are A, P, and U.
A matrix represents authorship: there’re arrows pointing to post nodes from a user node for posts that are written by the user. The P matrix represents involvement: there’re arrows pointing to user nodes from a post node for users who either writes or comment below the post. Finally, the U matrix represents reply: there’re arrows pointing to user node A from another user node B if A has replied to B under any post.
The advantage of this graph embedding is that posts nodes are very close if they are written by the same users. On the other hand, even if posts are written by different users, their nodes are still connected through involving users in common, and the closeness of the posts in our graph is based on the similarity between the group of users that interact with each of them.
Graph 2
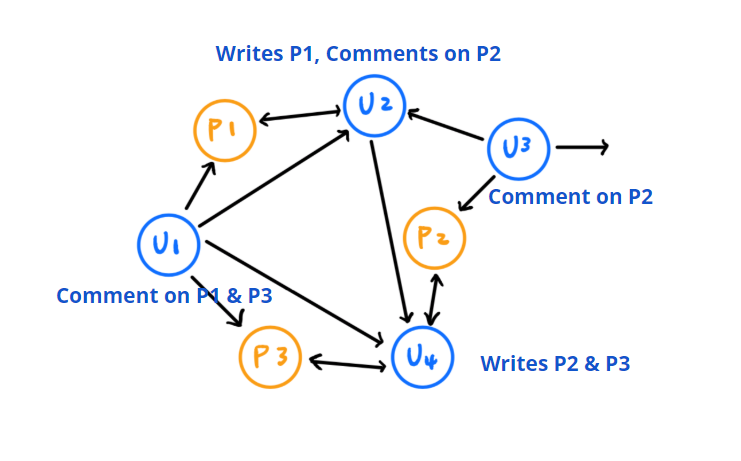
Graph 2 also consists two node types: post nodes and user nodes with similar relationship with graph 1. The matrices are also represented as A, P, U. Our Graph 2 also embed similar relationships to Graph 1 but with a more intuitive flow. The matrices are also represented as A, P, and U. However, these relationships are defined slightly different from those in Graph 1.
A matrix in Graph 2 represents the same authorship relationship but in an opposite direction: whenever a user writes the post, the post node will point to the user. The P matrix also represents involvement similarly but with an opposite direction: whenever author writes the post, the author will point to the post node, and whenever a user replies under a post, the user node will also point to the post node. The U matrix represents user interactions, specifically reply behavior: author will point to user when the author is replied by the user, and user A will point to user B when user B is replied by user A.
The difference between these two graphs is that the second one adds weights to users of first level replies who directly comment below the main post by adding extra arrows. For this specific embedding, post nodes are still close if they are written by the same users. On the other hand, they are also close because they have many first-level repliers in common.
7. Machine Learning Deployment
Since we are performing binary classification with imbalanced dataset, True Positive and True Negative play more crucial roles in our classification model. Because graph techniques will be significantly influenced by traditional balancing data technique like over-sampling and under-sampling, we will evaluate our model with following metrics: Recall and Precision, to catch more potential hateful posts. We also present AUC as an indication of how well our model is distinguishing between hateful and benign post.
Hinreddit presents three methodologies over following graph techniques: Node2vec, Metapath2vec, and DGI. We use these three semi-supervised learning techniques to get the representational learning on the graph. Typically, we will use node2vec, metapath2ec, and deep graph infomax (DGI) since they are well-explained on features and popularly addressed in different papers on graph neural networks. We expect to use our embeddings to cluster the post nodes into two different communities: hateful posts and normal posts. Node2vec and metapath2vec contain only graph information, while DGI has the power to include other features about the nodes. Node2vec and metapath2vec are similar: both of them can automatically exploit the neighborhood structure through sampled paths on the graph by random walk. Metapath2vec demands more on memory and speed since it also catches information about different metapaths. DGI does not rely on random walk: it rather replies on maximizing mutual information between patch representations and corresponding high-level summaries of graphs, which is the post features in our case.
8. Experimental Result
Baseline Model Result
Our baseline model is built based on our investigation of label statistics, and include features: length of text, number of comments, subreddit, upvote score, and a boolean feature of whether it includes some sensitive words.
| Estimator | Precision | Recall | AUC | ACC |
|---|---|---|---|---|
| Logistic Regression | 0.1346 | 0.7355 | 0.7630 | 0.7883 |
| RandomForest | 0.1422 | 0.3900 | 0.6429 | 0.8744 |
| GradientBoosting | 0.6258 | 0.1163 | 0.5566 | 0.9596 |
From the table above, we can observe that the performances logistic regression produces relatively high recall, meaning that it identifies more hateful posts from all existing ones, while producing low precision, meaning that only a small portion of posts it identifies as hateful are truly hateful. On the other hand, gradient boost classifier produces opposite results with lower recall and higher precision. Both logistic regression and gradient boost classifier have higher AUC compared to random forest, meaning that they are both better at distinguish between hateful posts and benign posts.
Hinreddit Result
Besides classifying a single post as hateful or not, we also tried identifying controversial subreddit, or which subreddits should be quarantined, based on the ground truth labels given by Reddit. The controversial subreddit detection shows a better performance in terms of all the metrics we use, and implies the possibility that our model may suit this purpose better.
Embedding Analysis
We will analyze graph embedding feature by fitting in Logistic Regression in hateful post detection, controversial community detection, and subreddit community detection, and we will see the TSNE of the embedding. In the following TSNE graphs, the left side presents network of normal and hateful posts, and the more hateful clusters will be in darker red. The right side presents network of posts in different subreddits, and different colors represent corresponding subreddits.
- Graph 1
| Task | Algorithm | Precision | Recall | AUC | ACC |
|---|---|---|---|---|---|
| controversial community detection | Node2vec | 0.9362 | 0.8225 | 0.8161 | 0.8196 |
| controversial community detection | Metapath2vec | 0.9079 | 0.7893 | 0.7587 | 0.7754 |
| subreddit community detection | Node2vec | NA | NA | NA | 0.8052 |
| subreddit community detection | Metapath2vec | NA | NA | NA | 0.7027 |
| hateful post detection | Node2vec | 0.0569 | 0.5436 | 0.5737 | 0.6013 |
| hateful post detection | Metapath2vec | 0.0559 | 0.5413 | 0.5694 | 0.5952 |
| hateful post detection | DGI | 0.1379 | 0.7172 | 0.7593 | 0.7979 |
Graph 1 Node2vec Normal Posts vs. Hateful Posts
Graph 1 Node2vec Subreddits
Graph 1 Metapath2vec Normal Posts vs. Hateful Posts
Graph 1 Metapath2vec Subreddits
- Graph 2
| Task | Algorithm | Precision | Recall | AUC | ACC |
|---|---|---|---|---|---|
| controversial community detection | Node2vec | 0.9497 | 0.8772 | 0.8597 | 0.8692 |
| controversial community detection | Metapath2vec | 0.9052 | 0.7771 | 0.7503 | 0.7649 |
| subreddit community detection | Node2vec | NA | NA | NA | 0.8364 |
| subreddit community detection | Metapath2vec | NA | NA | NA | 0.6409 |
| hateful post detection | Node2vec | 0.0644 | 0.6250 | 0.6126 | 0.6012 |
| hateful post detection | Metapath2vec | 0.0535 | 0.5298 | 0.5586 | 0.5849 |
| hateful post detection | DGI | 0.0772 | 0.7172 | 0.6561 | 0.6531 |
Graph 2 Node2vec Normal Posts vs. Hateful Posts
Graph 2 Node2vec Subreddits
Graph 2 Metapath2vec Normal Posts vs. Hateful Posts
Graph 2 Metapath2vec Subreddits
Embedding + Baseline Feature Hateful Post Result
- Graph 1
| Estimator | Algorithm | Precision | Recall | AUC | ACC |
|---|---|---|---|---|---|
| Logistic Regression | Node2vec | 0.1306 | 0.7275 | 0.7565 | 0.7830 |
| Logistic Regression | Metapath2vec | 0.1284 | 0.7206 | 0.7520 | 0.7808 |
| Logistic Regression | DGI | 0.1379 | 0.7172 | 0.7593 | 0.7979 |
| RandomForest | Node2vec | 0.6143 | 0.0490 | 0.5238 | 0.9584 |
| RandomForest | Metapath2vec | 0.6032 | 0.0433 | 0.5210 | 0.9582 |
| RandomForest | DGI | 0.2939 | 0.1505 | 0.5673 | 0.9487 |
| GradientBoosting | Node2vec | 0.6395 | 0.1072 | 0.5523 | 0.9596 |
| GradientBoosting | Metapath2vec | 0.6081 | 0.1026 | 0.5498 | 0.9591 |
| GradientBoosting | DGI | 0.5611 | 0.1151 | 0.5556 | 0.9587 |
- Graph 2
| Estimator | Algorithm | Precision | Recall | AUC | ACC |
|---|---|---|---|---|---|
| Logistic Regression | Node2vec | 0.1313 | 0.7320 | 0.7588 | 0.7833 |
| Logistic Regression | Metapath2vec | 0.1314 | 0.7355 | 0.7601 | 0.7827 |
| Logistic Regression | DGI | 0.1303 | 0.7628 | 0.7686 | 0.7740 |
| RandomForest | Node2vec | 0.6125 | 0.0559 | 0.5272 | 0.9585 |
| RandomForest | Metapath2vec | 0.5692 | 0.0422 | 0.5204 | 0.9580 |
| RandomForest | DGI | 0.2146 | 0.1984 | 0.5831 | 0.9352 |
| GradientBoosting | Node2vec | 0.5935 | 0.1049 | 0.5509 | 0.9590 |
| GradientBoosting | Metapath2vec | 0.6174 | 0.1049 | 0.5510 | 0.9592 |
| GradientBoosting | DGI | 0.6062 | 0.1334 | 0.5648 | 0.9596 |
9. Discussion
Result Analysis
As seen above, we have obtained fairly low precisions and recalls with our current user-post embeddings and models. In terms of all the metrics, our graph embedded network of posts and users does not improve much from what the baseline model already provide. The results can be understand together with our Exploratory Data Analysis. The data has shown that only 7% of users have ever engaged in hateful posts, and among them almost half of users have themselves write posts/comments that are labeled as hateful. Moreover, for users who have engaged in hateful posts, only around 28% of their posted speeches are labeled as hateful. These numbers suggest users have a small chance of creating their own hateful posts/comments although they have engaged in any of the hateful posts. Furthermore, even if they have created any, it is not a consistent behavior. This then demonstrates that our initial hypothesis might not be accurate as mere relationships of users' reply behavior and authorship cannot provide much useful information in identifying hateful posts, which is then confirmed by our model results.
Due to the fact that our graph representation only embeds authorship and reply behavior, and as Node2vec and Deep Graph Infomax both are greedy in the training process, the models cannot clearly distinguish between hateful and benign posts, which is shown by the AUC values that are only slightly higher than, or even lower than, 0.5 and our baseline models that make use of post-related features.
Possible Improvement
First possible improvement can be done in the labeling process. To label our reddit data, we have trained an NLP classifier with labeled Wikipedia comments as well as pretrained Wikipedia vocabularies. It would be better if we can obtain labeled social platform data, such as labeled tweets to be trained with pretrained Twitter vocabularies provided by Glove.
Another possible improvement, which we originally would like to implement, is to include more user-to-user relations in our graph representations. Some examples include subreddit subsription lists and friends connection. We currently have a hard time including these relationships because user information features are still in development in the API we use, PushShift. Although Reddit's own API, PRAW, offers related features, it unfortunately employs a different system of user ID from what PushShift uses, and we are unable to connect them to obtain user information. This can be done as soon as PushShift succesfully develops user information features.
Finally, we can also improve our algorithm to make use of the timeline data we obtain along with posts and comments. By adding a time feature, we can construct sequence nodes and feed in to Recurrent Neural Network models, such as Long Short-Term Memory.
10. Miscellaneous
Reference
@paper{Hou/Ye/2017,
title={HinDroid: {An Intelligent Android Malware Detection System Based on Structured Heterogeneous Information Network}},
author={Hou, Ye, Song, Abdulhayoglu}
year={2017}
}@inproceedings{Fey/Lenssen/2019,
title={Fast Graph Representation Learning with {PyTorch Geometric}},
author={Fey, Matthias and Lenssen, Jan E.},
booktitle={ICLR Workshop on Representation Learning on Graphs and Manifolds},
year={2019},
}@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}@course{Koutra/2018,
title={Mining Large-scale Graph Data},
author={Danai Koutra},
link={http://web.eecs.umich.edu/~dkoutra/courses/W18_598/},
year={2018}
}@collection{src-d/2019,
title={Awesome Machine Learning On Source Code},
author={src-d},
link={https://github.com/src-d/awesome-machine-learning-on-source-code},
year={2019}
}Credits
Hinreddit is developed by Chengyu Chen, Yu-chun Chen, Yanyu Tao, and Shuibenyang Yuan.
For anyone who are interested in through anlysis of our project you may find a through report Here and the implementation source code in our Github Repository